-
브라우저 동작원리를 알아야 하는 이유가 무엇인가요?개발 블로깅/Improving Performance 2021. 10. 30. 01:00
💡 해당 글은 React의 SSR인 Next.js 프레임워크에 의존하여 작성된 글입니다.
그러나 전체적인 맥락과 핵심 내용을 이해하시는 데는 큰 문제는 없습니다.
프론트엔드 주니어 개발자가 꼭 알아야 하는 기본지식 중 하나로 많이 소개되고 있는 '브라우저 동작 원리'
취업이나, 이직 준비를 해봤다면 무조건 들여다봤을 내용인 만큼, 브라우저가 어떻게 동작하는지에 대해서는 프론트엔드 개발자라면 이미 어느 정도는 알고 있을 것이라 생각한다.그러나 개발자에게 필요한 기본 지식이라고 해서 어찌어찌 들여다보고 이해는 했는데... 도대체 이게 왜 필요한 걸까?
지금까지 이런 지식 없이도 개발은 잘만 해왔고, 왠지 앞으로도 굳이 필요 없을 것 같긴 한데..
브라우저 동작원리에 대해 상세하게 다루는 블로그 글과 영상은 굉장히 많이 봐 왔지만, 이러한 내용들이 우리에게 대체 왜 필요한지, 어떠한 경우일 때 이러한 지식이 빛을 발하는지에 대해서는 정작 설명을 해주는 곳이 많지 않다.나 역시 작년까지만 해도 브라우저의 동작원리에 대해 깊게 파고들어 보기만 했지, 실제로 이것이 왜 필요한지는 아직 체감하지는 못한 상태였다. 언젠가는 아직 내가 겪어보지 못한 문제를 해결하기 위한 기본 지식이 될 것이라는 생각만 가지고 있었기 때문에..
그러나 현재 소속된 서비스의 SEO 팀 내에서 6개월 정도의 활동을 마친 뒤, 지금은 프론트엔드 개발자가 브라우저의 동작원리를 왜 알아야 하는지 몸소 깨달은 상태이고, SEO 관련 업무를 수행하는 과정에서 이러한 지식이 엄청나게 큰 활약을 한 만큼 실제로 그것을 알아야만 문제를 찾고, 정의하고, 해결할 수 있었던 경험들을 많이 겪게 되었다.
어떻게 보면 SEO 팀에 합류하게 된 것은 엄청나게 운이 좋았다.
여기까지 읽었으면, 도대체 그 브라우저 동작원리를 가지고 수행했던 업무가 무엇이었는지 궁금할 것이다.
그럼 시작하기 전에 커피 한 모금 마신 뒤 ☕️, 한번 다 같이 출발해보도록 하자.
우리가 브라우저 동작원리를 왜 알아야 하는지!
팀 리더가 당신에게 업무를 지시했다.
"우리 웹 사이트 화면을 할 수 있는 것은 무엇이든 해서, 최대한 빠르게 보여지도록 개선시켜주세요."
자, 우리는 Next.js로 구현된 특정 웹 페이지를 빠르게 로딩되도록 해야 한다.
어떻게 진행해 볼 것인가.💡 왜 Next.js로 구현된 웹페이지로 예시를 잡은 건가요?
-> Next.js가 Server Side Rendering이기 때문이다. 렌더링 방식 특성상 Server Side Rendering이 Client Side Rendering보다 초기 로딩 속도가 빠르다. 자세한 건 SSR, CSR에 대해 따로 검색해보길 바란다. 여기서는 깊게 다루지 않는다.문제 정의
우리가 알고 있는 SSR(Server Side Rendering)이란 아래와 같다.
'웹 서버 단에서 미리 화면을 렌더링해서 브라우저로 전달해 빠르게 화면을 보여준다.'
아래의 네트워크 탭을 확인해보자.

특정 페이지를 요청해서 받아온 첫 번째 리소스 Type이 document이다.
이 document가 무엇일까? 바로 서버 단에서 미리 렌더링 과정을 거쳐서 만들어진 Render Tree 정보를 가진 문서이다.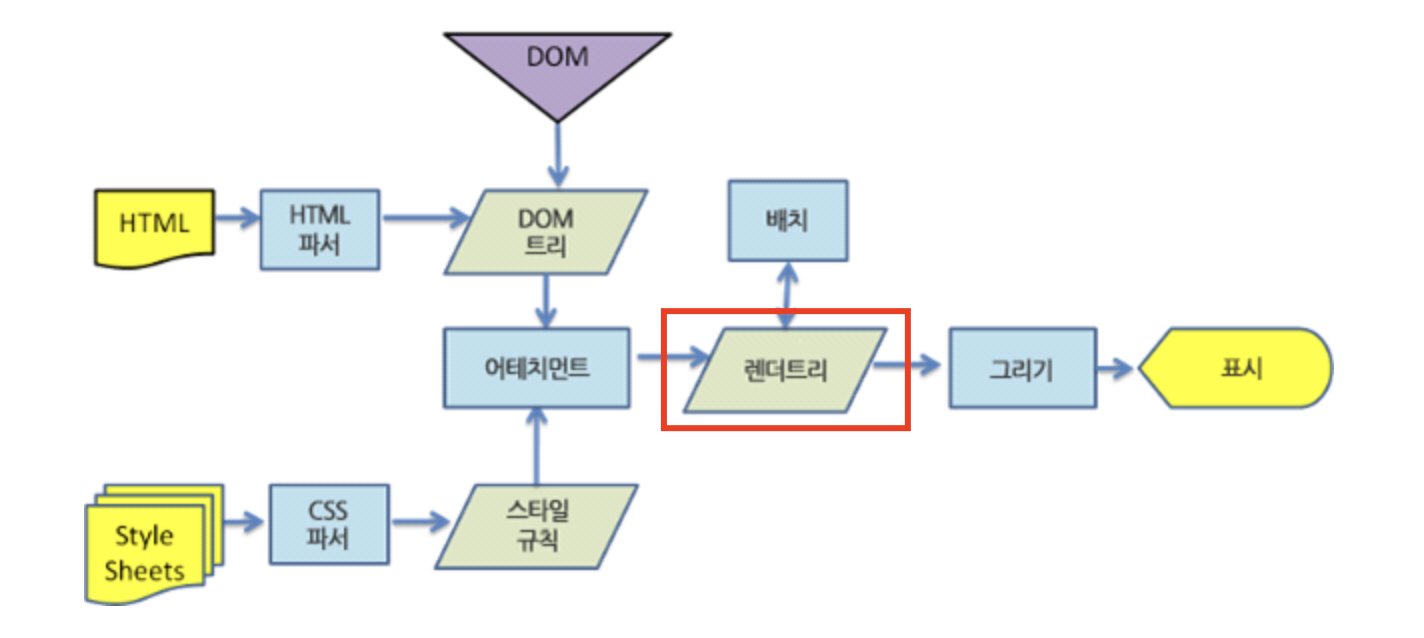
naverD2 브라우저 동작원리 중, Webkit 동작 Flow Webkit의 렌더링 동작 과정에 표시한 부분처럼, 브라우저는 이 document만을 가지고 브라우저 화면 내의 엘리먼트 배치와 그리기만 하면 된다.
그러면 여기서 우리가 해결해야 할 문제를 한번 정의해보자.
'document 페이지를 화면에 빠르게 보여주려면 어떻게 해야 할까?'
우선 바로 위에 브라우저 동작원리 중 document를 생성하는 부분, 즉 렌더 트리를 생성하는 과정을 공략해야 할 필요가 있다.
렌더링 요소 최적화
💡오해의 소지가 생길 내용을 미리 공유
아래에서부터는 서버 사이드에서 렌더링 된 document 문서를 최적화시키는 과정을 계속해서 거쳐나갈 것이다.
실제 브라우저에서는 이미 렌더링이 완료된 document만 받아서 화면이 그리기만 하면 되기 때문에, 어쩌면 브라우저의 동작원리와는 관련이 없지 않냐는 의문이 생길 수도 있다. 하지만 이 document가 생성되는 과정도 브라우저의 동작원리와 다르지 않다. 단순히 브라우저에서 하는 동작 과정을 실제로 브라우저에서 하냐, 서버 단에서 하냐의 차이일 뿐이다. 그렇기 때문에 해당 지식을 기반으로 document의 개선점을 계속해서 찾아낸다는 점은 차이가 없다.
지금부터 브라우저 동작원리 중 'Render Tree' 부분을 먼저 공략해보자.Render Tree를 최적화시키려면 무슨 방법이 있을까?
첫 번째 방법으론, 어쩌면 허무할 수도 있는 답을 먼저 꺼내보겠다. 당연히 화면에 보여줄 렌더링 요소를 줄이면 된다.여기서 내가 줄여야 한다는 것은 원래 화면 상에 보여주려던 요소들을 줄이라는 게 아니라, '팝업 창', '설정 메뉴 바'와 같이 유저의 특정 액션이 있어야만 보여지는 요소들을 초기 로딩 시에 바로 렌더링 하지 않도록 줄이는 것을 말한다.

아마 막 시작한 개발자들은 초기 로딩 시 숨어있어야 할 요소들을 스타일 속성으로 `display: none;` 이나 'opacity: 0;'으로 설정을 하는 경우가 많을 것이다.
div { display: none; opacity: 0; visibility: hidden; }opacity:0의 경우에는 화면에는 보이지 않겠지만 해당 요소는 그대로 렌더링 된 채 투명도를 100% 투명하게 설정하는 것이다. 그러므로 실제 화면에서는 해당 요소가 존재한다.
visibility: hidden의 경우에도, 요소 자체는 존재하지만 단순히 해당 요소를 보이게 하는지 여부를 설정한다.
반면 display: none의 경우에는 실제 화면에서 제외하는 것이므로 렌더링 시 display:none으로 설정된 요소는 Render Tree에서 제외된다. 그러나 이것 또한 처음 페이지를 요청할 때 렌더링이 되지는 않지만 SSR 환경에서는 브라우저에게 페이지 전달을 위해 document에 함께 종속시켜 버리게 되어 초기 로딩 시 함께 네트워크를 통해 받아오는 문제가 있다.그러면 확실하게 초기 로딩 시 필요한 요소들만 받아올 수 있는 방법이 무엇이 있을까?
우리는 Code Splitting을 이용해서 코드를 Chunk 형태로 따로 떼어낼 수 있다.
import("./Math").then(math => { console.log(math.add(16, 26)); });const OtherComponent = React.lazy(() => import('./OtherComponent'));
Code Splitting은 Webpack 등의 번들러가 지원하는 기술로 전략적으로 각 코드를 분할할 수 있고, 특정 컴포넌트를 dynamic 하게 import를 해서 별도로 요청할 수 있다.
Code Splitting을 이용한다면 페이지에서 바로 보여줄 필요가 없는 요소들은 별도의 청크 파일로 분리해서, 실제로 초기 로딩에 필요로 한 요소들만 가지고 렌더링 처리를 할 수 있게 된다.
초기로 렌더링 할 범위가 많이 줄어들기 때문에, 렌더링 속도 개선과 document 리소스 크기가 감소하여 통신 속도도 증가하게 된다. 이후 아직 요청하지 않은 Chunk Code들은 실제로 필요한 타이밍에 별도로 호출하여 사용할 수 있다.
그러면 Code Splitting을 통해 초기 로딩 시 보여줄 필요가 없는 요소들은 전부 덜어내고, 필요로 한 요소들만 렌더링을 할 수 있도록 개선시켰다고 해보자.
그럼에도 조금 더 개선시킬 방법이 없을까 고민을 해본다.화면에 보여줄 요소들을 요청할 때마다 그때그때 항상 렌더링을 해주어야 할까?
렌더링 한 document 페이지를 그대로 사용할 수는 없을까?Next.js에서는 데이터로 인해 항상 정보가 달라져야 하는 웹 페이지가 아니라면, 빌드 타임에 미리 정적 페이지로 렌더링 시켜 해당 document를 바로 브라우저로 전송할 수 있다.
API로 요청해서 일부 데이터를 가져와야 하는 경우라도 해당 데이터가 변하지 않는 고정된 데이터라면, getStaticProps를 통해 빌드 타임에 데이터를 요청해서 가져온 후 미리 렌더링을 처리할 수도 있다. 그러면 브라우저에서 페이지 요청이 있을 때마다 새롭게 렌더링을 하지 않고 바로 document 페이지를 전달하게 된다.
예시로 Next.js 공식문서의 예시 코드를 봐보자.// pages/Blog.js function Blog({ posts }) { return ( <ul> {posts.map((post) => ( <li>{post.title}</li> ))} </ul> ) } export async function getStaticProps() { const res = await fetch('https://.../posts') const posts = await res.json() return { props: { posts, }, } } export default BlogBlog라는 페이지가 있고, 서버 사이드 단에서 posts 데이터를 요청 후 Blog 컴포넌트에게 Props로 보내주도록 되어있다.
getStaticProps()의 경우에는 유저가 요청이 있을 때마다 동작하지 않고 빌드 타임 시 한 번만 동작하기 때문에, 렌더링 이후에 Blog 페이지를 요청하면, 빌드 이후 posts 데이터가 새롭게 업데이트 되었어도 빌드 타임에 받아왔던 과거의 posts 데이터로 화면에 보여주게 될 것이다.이미 Blog 페이지는 빌드 타임에 변하지 않는 정적 페이지로 렌더링이 되어버렸고, 웹 서버는 유저가 페이지를 요청할 때마다 다시 렌더링 하지 않고, 미리 렌더링 된 document만 보내주면 되기 때문이다.
Next.js의 Static Page 처리에 대해 더 자세한 내용은 Next.js 공식문서를 참고하면 된다.(다른 프레임워크에 대해서는 자세히 알아보지는 못했지만, 변하지 않는 정적 페이지라면 분명히 미리 렌더링 한 document를 그대로 전달할 수 있는 방법이 있을 것으로 생각된다.)
이렇게 변하지 않는 정적인 페이지까지 렌더링 요소를 없애 개선시켰다고 해보자. 여기까진 간단했다.
정적인 페이지는 쉽게 해결이 되었는데, 그럼 리스트 페이지와 같이 동적으로 변하는 페이지는 어쩔 수 없는 것일까?
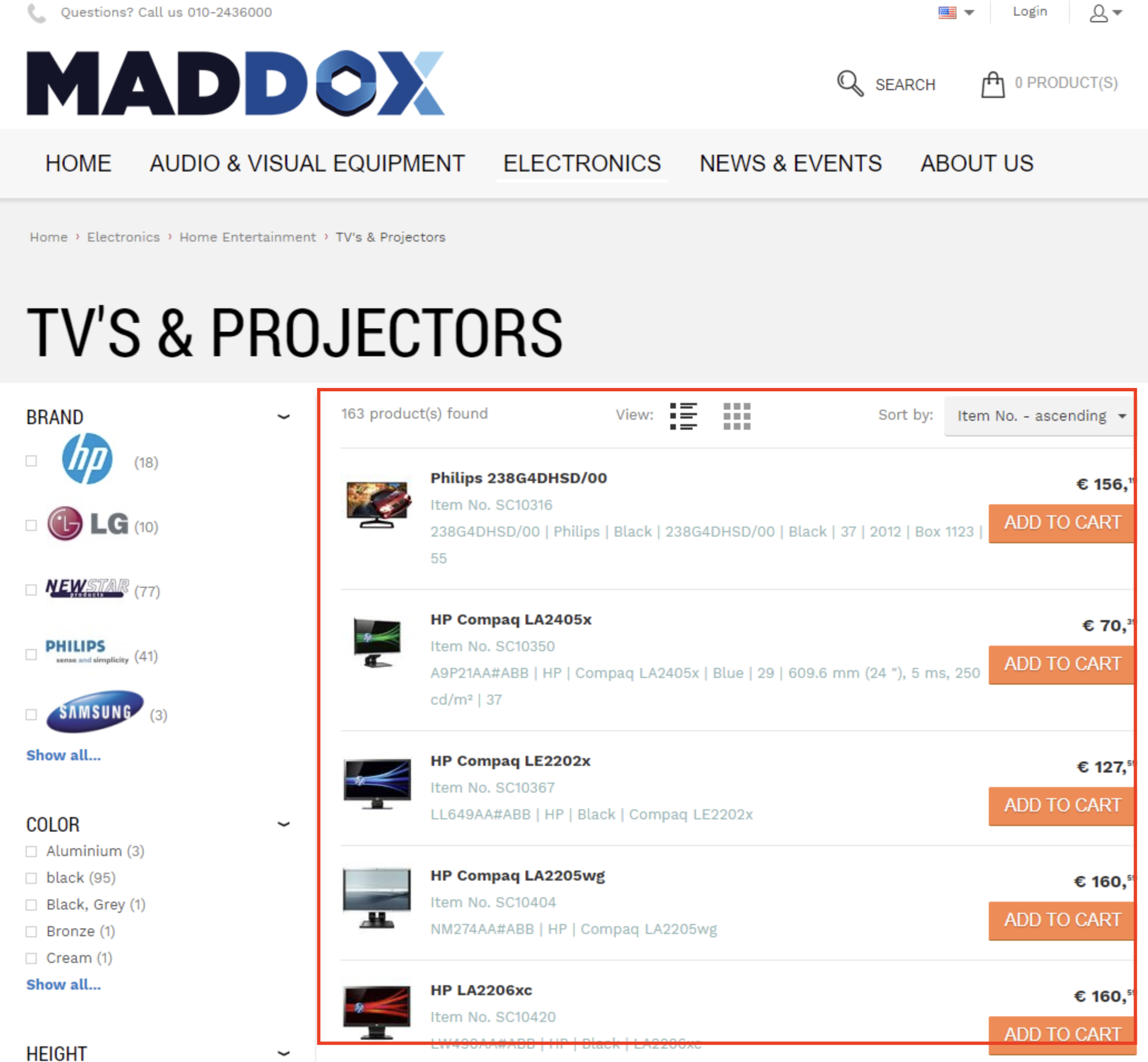
MADDOX List Page 
예시로 위 이미지들에 표시한 부분처럼, 데이터가 변하는 영역은 당연히 그때그때마다 보여줄 화면이 다르게 때문에 어쩔 수 없다고 치자.
그러면 그 외에 고정된 다른 영역이라도 렌더링을 하지 않을 방법이 없을까?
페이지 전체에서 동적으로 변하는 영역이 페이지의 일부이고 나머지는 변하지 않을 영역이라면, 이러한 렌더링 과정을 일일이 하기에는 너무 억울할 것 같다.변하지 않을 영역만 따로 document 조각으로 만들 수 있는 방법을 찾아보니 ESI(Edge Side Includes)라는 기술을 발견할 수 있었다.
내용이 많이 어려울 건데, 간단히 설명하자면 '웹 페이지의 조각을 다른 웹 페이지에 포함시키는 마크업 언어 기술'이다. 기존에 있는 document 페이지에서 특정 document 페이지 조각을 추가할 수 있는 것이다.
그런데 ESI 자체를 이해하고 사용하려니, 현재 우리 레벨에서는 너무 어렵다..😓
하지만 감사하게도, ESI를 기반으로 한 React 단에서 쉽게 사용할 수 있는 React-esi 모듈이 있다.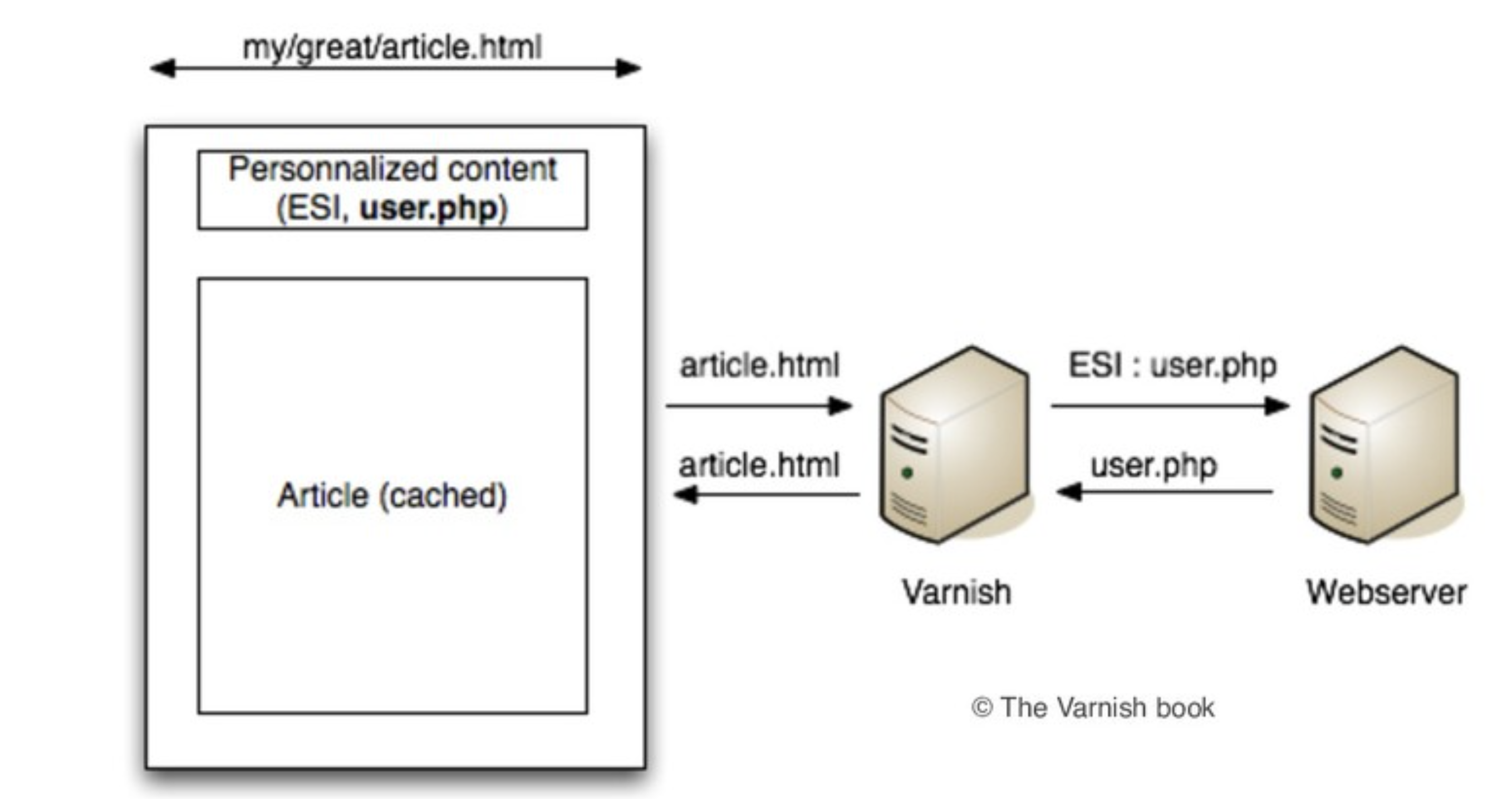
서버 단에서 정적인 엘리먼트들은 미리 렌더링 후 document페이지로 캐시 서버에 캐싱해 놓는다.
유저가 my/grate/article.html을 캐시 서버에게 요청하면, 캐시 서버가 동적으로 변하는 영역만 따로 실제 웹 서버에서 요청해서 가져온 뒤 전체 페이지로 합친 후 유저에게 전달하는 방식이다.
(중간에 Varnish라는 캐시 서버는 React-esi에서 소개하는 다른 캐시 서버들을 이용해도 상관없다.)간단히 예시 코드를 봐보자.
// pages/index.js import React from 'react'; import withESI from 'react-esi'; import MyList from 'components/MyList'; const MyListESI = withESI(MyList, 'MyList'); // The second parameter is an unique ID identifying this fragment. // If you use different instances of the same component, use a different ID per instance. const Index = () => ( <div> <h1>React ESI demo app</h1> <MyListESI greeting="Hello!" /> </div> );우선 Index라는 전체 페이지가 있다.
제목을 보여주는 <h1> 태그 부분은 변하지 않을 정적인 요소이고, MyList는 동적으로 변할 데이터 영역이다.MyList컴포넌트는 ESI HOC를 이용해 감싸서 컴포넌트를 간단히 배치하면 된다.
그러면 ESI를 이용하는 컴포넌트 내부는 어떤 모습일까? MyList의 내부를 확인해보자.
// components/MyList.js import React from 'react'; export default class MyList extends React.Component { render() { return ( <section> <h1>A fragment that can have its own TTL</h1> <div>{this.props.greeting /* access to the props as usual */}</div> <div>{this.props.dataFromAnAPI}</div> </section> ); } static async getInitialProps({ props, req, res }) { return new Promise(resolve => { if (res) { // Set a TTL for this fragment res.set('Cache-Control', 's-maxage=60, max-age=30'); } // Simulate a delay (call to a remote service such as a web API) setTimeout( () => resolve({ ...props, // Props coming from index.js, passed through the internal URL dataFromAnAPI: 'Hello there' }), 2000 ); }); } }정적인 페이지 내에서 특정 요소만 동적으로 동작할 수 있었던 핵심이 바로 getInitialProps이다.
getInitialProps는 Next.js에서 유저 요청이 있을 때마다 서버 사이드 단에서 렌더링 후 브라우저에게 페이지를 반환하는 것인데, ESI에서는 특정 컴포넌트 내에 동작하도록 되어있다.
유저 요청이 발생하면 해당 컴포넌트만 별도로 getInitialProps를 통해 서버 사이드 동작을 시켜 PreRendering 된 document를 내려주게 되는 것이다.
그러면 전체 페이지 중 정적인 document는 미리 저장된 캐시 서버에서 기다렸다가 별도로 요청하여 가져온 동적인 document를 가져오면, ESI 처리로 분리되어 있던 document가 하나의 페이지 합쳐진 후 유저에게 내려준다.이러한 방식을 통해 정적으로 변하지 않는 영역에 대한 렌더링 요소를 없앰으로써 document를 생성하는 속도를 개선시킬 수 있다.
React-esi에 대한 자세한 내용은 아래 React-esi 링크를 참고하길 바란다.GitHub - dunglas/react-esi: React ESI: Blazing-fast Server-Side Rendering for React and Next.js
React ESI: Blazing-fast Server-Side Rendering for React and Next.js - GitHub - dunglas/react-esi: React ESI: Blazing-fast Server-Side Rendering for React and Next.js
github.com
이렇게 동적 페이지의 개선까지 진행할 수 있었다. 이제는 불필요한 렌더링은 없애고 필수로 무조건 렌더링을 해주어야 할 요소들만 남은 상태이다.
그러면 이젠 더 이상 할 게 없을까? 무엇을 더 할 수 있지?
다시 한번 문제 정의
우리는 1. 초기 로딩에 불필요한 요소들을 모두 제거했고, 2. 변하지 않는 정적인 영역에 대해 불필요한 렌더링 과정을 없앴다.
그럼 남은 부분은 무엇인가? 바로 동적인 영역이다.
이제는 리스트 페이지와 같은 동적으로 항상 변하는 영역에 대해 개선점을 찾아보자.동적인 영역은 무조건 렌더링을 해야 한다. 그러면 우리가 해결해야 할 문제는 '동적인 영역을 빠르게 렌더링 하도록 해야 한다'가 될 것이다.
초기 로딩 시 렌더링을 빠르게 하려면 어떤 방법이 있을까? 렌더링 할 요소를 줄인다면 빨라지겠지만, 이미 위에서 불필요한 렌더링 요소를 모두 줄인 상태이다.
그러면 이번에 신경을 써 볼 요소는, 렌더링 중에 처리되지 않아도 되는 불필요한 태스크들을 줄이는 일이다.
그러면 메인 스레드가 렌더링 처리에 집중할 수 있게 된다.예시로 아래 코드를 봐보자.
import firebase from 'firebase'; const Home = () => { useEffect(() => { firebase.init(); // 로그를 수집하는 서버와의 커넥션을 위해 initilize를 선 처리. },[]); const onClick = () => { firebase.sendEvent('eventName', {name: 'inyong'}); } return( <div> <button onClick={onClick}>click</button> </div> ); } export default Home;위 코드처럼 firebase 모듈을 통해 버튼을 클릭하면 로그를 수집하는 코드가 있다고 가정해보자.
(흐름 이해를 돕기 위한 임시 코드이다. 실제 firebase 사용법은 다르다!)페이지가 렌더링을 할 때 선언된 firebase 모듈을 가져오고 있다. 이는 유저가 페이지를 요청하면, 서버 사이드 단에서 렌더링을 할 때 어느 정도 firebase 모듈을 포함하게 되어 그만큼 초기 페이지 사이즈가 증가하게 된다.
또한 브라우저에는 할당된 스레드의 한계가 있다. 초기 로딩에 모듈이 추가될 때마다, 선언된 해당 모듈을 처리하는데 필요한 스레드 태스크가 발생할 것이다. 렌더링을 하는데 필요로 한 스레드가 다른 곳에 쓰이는 만큼 렌더링이 처리는 시간은 당연히 지연될 수밖에 없다.
그러면 firebase의 모듈이 초기 렌더링에 영향을 주지 않고 Lazy 하게 불러오도록 할 수는 없을까?
import { sendEventLog } from './firebase'; const Home = () => { const onClick = () => { sendEventLog('eventName', {name: 'inyong'}); } return( <div> <button onClick={onClick}>click</button> </div> ); } export default Home; -------------------------------------------------------------------- // firebase.js let firebase = null; const checkInitFirebase = async () => { if(!firebase) { firebase = await import('firebase'); // lazy하게 모듈 불러오기; firebase.init(); } } export const sendEventLog = async (eventName, Log) => { await checkInitFirebase(); firebase.sendEvent(eventName, Log); }위 코드를 보면, 초기 로딩에는 firebase 관련해서 아무것도 수행되는 것이 없다.
나중에 유저의 액션에 의해 로그 수집이 필요한 상황이 발생했을 때, firebase 모듈을 import 해서 불러와 init 처리 후 이벤트 로그를 수집하게 된다.이렇게 하면 이전과는 다르게 초기 렌더링 과정에서 firebase를 처리하는 태스크가 발생하지 않아, 메인 스레드가 렌더링 처리를 하는데 태스크를 더 집중할 수 있게 된다.
지금은 firebase라는 모듈을 예시로 들었지만, 이외의 Third party 라이브러리들도 이와 비슷한 방식으로 import 최적화를 시킬 수 있을 것이라 생각한다.이렇게 페이지 내 동적인 영역 가지 렌더링 과정을 개선시켜볼 수 있었다.
(분명히 이것 말고도 할 수 있는 작업이 더 많을 것이다. 그것은 스스로 찾아보고 연구해보면 좋을 것 같다.)
렌더링 부분에 있어서는 이제 어느 정도 개선이 된 것 같다. 하지만 우리는 계속해서 개선시킬 방법을 찾아야 한다.
우리가 할 수 있는 것이 또 무엇이 있을까?
또다시 한번 더 문제 정의
브라우저 동작원리에서 렌더링 이전에 처리하던 작업이 무엇이었는지 다시 한번 보자.
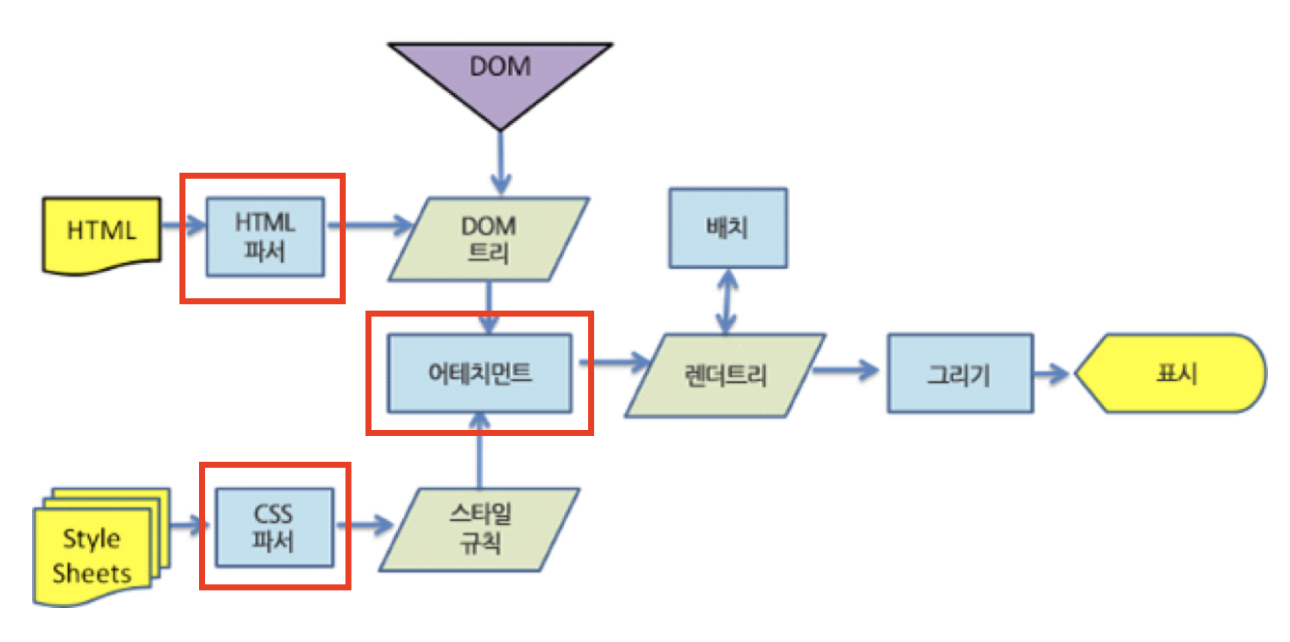
HTML과 CSS 파싱, 그리고 파싱 된 두 개의 Object Model을 융합하는 것이 있다.
더 나아가 이쪽 부분을 더 개선시킬 방법은 없을까?
( 그땐 그랬지.. "HTML 파싱...? 우리가 굳이 이런 것 까지 알아야 할 필요가 있을까?" )
Javascript 요소 최적화뜬금없이 제목에 'Javascript 요소 최적화'를 써놓아서 살짝 당황했을 수도 있다. 하지만 Javascript가 HTML 파싱에 많은 영향을 미치는 요소 중 하나이기 때문에 작성을 하였다.
브라우저의 동작원리에 따르면, 위에서 최적화시켰던 렌더 트리를 만들기 이전 단계인 HTML 파싱 중에 Script Code를 만나게 되면 HTML 파싱을 멈추게 된다. HTMl 파싱을 멈춘다는 것은 웹 화면의 렌더링의 지연을 뜻하고 이는 초기 로딩 속도를 늦추는 원인이 되는 것이다.
<body> <p> 첫 번째 텍스트 </p> <script src="..." /> <p> 두 번째 텍스트 </p> </body>위처럼 엘리먼트 요소 중간에 스크립트가 있다면, 아래의 '두 번째 텍스트' 엘리먼트 요소는 해당 스크립트 동작과 무관함에도 불구하고 스크립트 코드 동작이 끝날 때까지 마냥 기다리게 된다.
<body> <p> 첫 번째 텍스트 </p> <p> 두 번째 텍스트 </p> <script src="..." /> </body>그래서 초기 렌더링과 무관하게 동작하는 스크립트는 아래로 내려 엘리먼트 요소들이 먼저 렌더링 되도록 할 수 있다.
그러나 React나, Next.js와 같이 프레임워크 내에서는 <Body> 태그 내 스크립트 코드를 넣을 일이 많이 없다.
이와 달리, 초기 로딩에 필요로 한 외부 라이브러리, 또는 웹 폰트 등 사용으로 인해 <Head> 태그 내에서는 스크립트 선언을 많이 하곤 한다.
<head> <script type="text/javascript" async src='https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/MathJax.js?config=TeX-MML-AM_CHTML'></script> <script src="https://guppy.js.org//build/guppy_osk.min.js"></script> </ehad>위 코드를 보면 외부 JS 코드를 요청해서 불러오게 되어있다. 이 요소들은 초기 로딩 때 무조건 필요로 한 요소라고 가정해보자.
브라우저 동작 과정에서 보면, <Head> 태그에 선언된 내용들이 모두 실행이 완료된 후 <Body> 태그의 요소들이 파싱 되고 렌더링을 한다. 그래서 위 코드의 스타일과 JS 코드가 요청 후 브라우저로 다운로드될 때까지 <Body> 태그 내 요소들은 파싱 및 렌더링을 하지 못하고 기다려야 한다.
이러한 부분을 어떻게 개선할 수 있을까?<head> <script async type="text/javascript" async src='https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/MathJax.js?config=TeX-MML-AM_CHTML'></script> <script async src="https://guppy.js.org//build/guppy_osk.min.js"></script> </ehad><script> 태그 내 async 또는 defer 속성을 이용하면 해당 스크립트의 다운로드를 Background 단에서 요청하여 받아올 수 있다.
Background에서 처리한다는 것은 비동기 형식과 같이 별도의 스레드에서 다운로드를 진행하고, <Body> 태그는 async, defer로 다운로드하는 스크립트 태그를 기다리지 않고 HTML 파싱을 수행하는 것을 말한다.
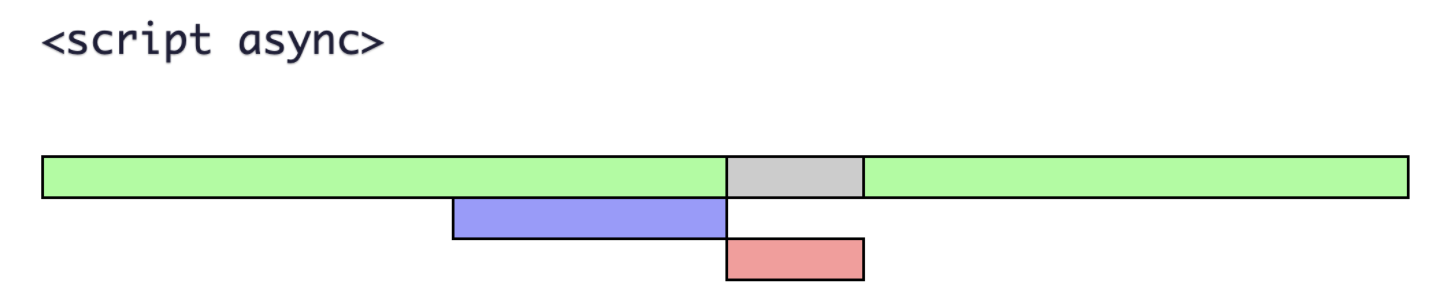
async과 defer의 차이를 간략하게 설명하면, defer는 스크립트 다운로드만 별도로 수행되고, 페이지가 파싱이 끝나고 렌더링을 시작할 때(정확히는 DomContentLoaded가 수행될 때)까지 기다렸다가 스크립트가 실행된다. 따라서 외부 스크립트의 다운로드 처리만 비동기로 처리 후 렌더링 시에는 HTML 파싱과 스크립트 실행이 순차적으로 일어나는 방식이다.
반면에 async는 서로 기다리지 않는다. 스크립트 로드부터 실행까지 별도로 수행하기 때문에, 스크립트가 레더링 전에 먼저 수행될 수도 있고 이후에 수행될 수도 있다. 그러므로 async는 초기 로딩에 종속적이지 않는 스크립트에 적합한 형태이다.
async/defer 관련해서 더 자세한 내용은 여기를 참고하면 된다.
HTML 파싱 관련해서 Script 최적화는 해결이 되었고, 이제 실제 HTML 파싱을 최적화할 수 있는 방법을 알아보자.
Hydrate HTML 파싱 최적화
예전에 Next.js의 Hydrate의 개념에 대해 소개하는 블로그를 작성했었다. 간단하게 설명하면 아래와 같다.
'서버 사이드 렌더링 된 Document 파일을 브라우저로 미리 전송하여 화면으로 출력한 뒤, 이후에 각 요소에 관련된 JS chunk 파일들을 다운로드하여 기존의 HTML Document와 Hydrate 과정을 거친다.'
Hydrate의 동작에서 주요하게 보아야 할 부분은 HTML이 구문 분석 및 파싱을 하면서 발생하는 렌더링의 지연 시간이다.

qanda.ai의 performance tab 중 위의 이미지는 Next.js 서버의 웹 페이지에서 요청한 Performance 탭이다.
자세히 보면 Next.js의 Next.js-before-hydraion을 처리하는 시간이 굉장히 길다. 그리고 그 과정에는 HTML 파싱을 하는 작업이 포함되어 있는 것을 알 수 있다.💡 위에서 Next.js는 서버 사이드 단에서 렌더링이 일어난다고 했는데, 왜 브라우저에서도 렌더링 이전 태스크인 HTML파싱을 하나요?
브라우저에서 동작하는 HTML 파싱은 화면 렌더링을 위한 파싱이 아니라, 화면에 띄워진 후, 실제 화면에 필요로 한 JS 파일들과 Hydration 처리를 하기 위한 파싱 작업이다. 정확히는 파싱을 포함해서 렌더링을 브라우저 단에서 한번 더 하는 것이다. 이에 대해 자세한 내용은 'Next.js Hydrate란?' 을 참고하길 바란다.🙇♂️Next.js-before-hydration의 정의는 아래와 같다.
- The time spent to download the initial html (which includes TTFB)
- The time spent to parse the initial html up through the necessary script tags that load the react libs
- The time spent to download those critical javascript chunk files
- The time spent to evaluate/execute those javascript chunk files, and load the react environment.
- 출처:https://stackoverflow.com/questions/66845811/next-js-before-hydration-next-js-hydration-and-fcp
이러한 Long Task로 동작하는 Hydration 과정을 어떻게 개선시켜 볼 수 있을까?
위에 정의한 Next.js-before-hydration를 다시 한번 보자.
1. 초기 HTML을 다운로드하고,
2. HTML을 파싱 하고,
3. 관련된 JS Chunk 파일을 다운로드하고,
4. 실행한다.위 정의를 통해 개선 방안을 한번 파고들어 보자.
우선 초기 HTML 다운로드하는 것에 대해 개선점은, 이미 앞단에서 코드 스플리팅, 그리고 Edge Side Includes 처리를 통해 HTML Document 자체를 개선한 것으로 볼 수 있을 것 같고, 이에 대한 개선점을 굳이 찾으려면 다운로드 속도인 네트워크 통신밖에 없을 것 같다.네트워크 영역은 이 글에서 다루는 브라우저 동작 과정이랑은 다른 영역이므로 패스하겠다.
다음은 HTML 파싱 부분이다. 우리가 어떻게 HTML 파싱을 개선시킬 수 있을까?
위에 설명한 것처럼, 브라우저 단에서 HTML 파싱이 일어나는 이유는 Hydration 처리 때문이다.
Next.js 환경에서 Hydration은 페이지가 정상 동작하게 하려면 무조건 거쳐야 하는 태스크이다.하지만 꼭 모든 페이지가 Hydration 처리가 되어야 할 필요가 있을까?
현재 보여지는 뷰 포트 내의 요소들만 Hydration 처리를 할 수 있다면, HTML을 파싱 하는 요소를 줄일 수 있을 것 같다.멋지게도 Hydration 자체도 Lazy 하게 처리할 수 있는 모듈이 있다.
GitHub - hadeeb/react-lazy-hydration: Lazy Hydration for Server Rendered React Components
Lazy Hydration for Server Rendered React Components - GitHub - hadeeb/react-lazy-hydration: Lazy Hydration for Server Rendered React Components
github.com
기존에는 서버 사이드 렌더링 된 document 페이지를 보여준 후, 해당 document와 관련된 JS Chunk 파일들을 모두 받아온 뒤, 페이지 전체적으로 Hydration 처리를 했다면, Lazy Hydration은 현재 화면에 보여지는 부분만 우선 Hydration을 처리하고, 이외 보여지지 않는 는 영역은 나중에 화면 뷰 포트에 들어오면 그때 hydration을 처리하는 방식이다.

그러면, Hydration을 처리하는 영역이 작아짐으로써, Next.js-before-hydration 처리에 대한 태스크가 줄어들고 웹 페이지 로딩 속도를 조금 더 향상 시킬 수 있다.
(개념에 비해 사용법은 간단하므로 따로 코드 설명은 하지 않겠다.)이 뿐 아니라, 이전에 Partial Hydration에 대해서도 블로그로 다루었었다.
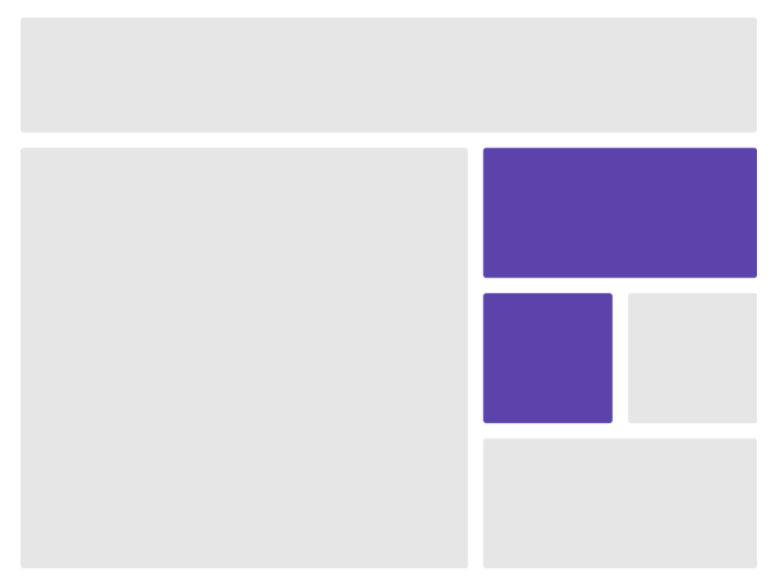
간략하게 설명하자면, Partial Hydration은 꼭 페이지 내의 모든 요소들이 Hydration을 할 필요 없이 유저 인터렉션이 필요로 한 요소들만 처리하면 된다 라는 것이다. 필요한 요소들만 Hydration 처리를 함으로써, Next.js-before-hydration 과정을 대폭 줄이고 로딩 속도를 끌어올리는 것이다.
Partial Hydration의 경우에는 Preact라는 개념을 알아야 하며, 생각보다 오래된 내용에 아쉽게도 현재는 따로 관리되고 있지 않는 듯하다. 그럼에도 이러한 동작 개념을 통해 HTML 파싱 최적화에 대한 인사이트를 얻을 수 있었다.이렇게 여러 방식의 Hydration 개선을 통해 HTML 파싱 요소 줄여버리고 초기 웹 페이지 로딩 속도를 개선시킬 수 있는 방법까지 알아보았다.
우리는 페이지를 빠르게 화면에 보여주는 작업을 시도해보기 위해, 렌더링부터 HTML 파싱 영역까지 깊게 파고들어 봤다. 아마 이보다 할 수 있는 것들이 더 많을 것이고, 더 깊게 파고들 요소들도 많을 것이다.
만약 브라우저 동작원리의 기본 지식이 없었다면 이렇게 깊게까지 들여다보고 우리가 해결해야 할 문제를 정의하기가 힘들었을 것이다.
지금까지 '브라우저 동작원리'를 통해 문제를 정의하고, 그 문제를 어떻게 해결하여 웹 성능을 향상시킬 수 있었는지 쭉 소개해보았다.
여기까지 읽고 나서, 만약 읽고 있는 여러분이 주니어 개발자라면 아마도 가장 크게 남겨진 의문점이 하나 있을 것이다.
'굳이 이렇게까지 성능을 개선시킬 필요가 있을까요? 실제로 유저가 느끼기에는 큰 차이 없을 건데..'
말대로 위에서 다룬 웹 성능들은 유저는 크게 느껴지는 바가 없을 것이다. 하지만 우리는 사이트에 접속하는 방문자는 사람뿐 만이 아니라, Google Bot과 같은 'Crawler'도 있다는 것을 잊으면 안 된다.
Crawler는 사람과는 다르게 이런 미세한 속도까지 캐치해낸다. 그렇기에 우리는 우리 사이트에 접근할 Crawler를 위해, SEO를 위해 작은 웹 성능까지도 신경을 써야 한다.
[SEO 관련 추가 설명]
혹시나 해서 아래와 같은 질문에 대한 설명을 추가로 더 작성해 보려고 한다. 이걸 설명하는 이유는 실제로 내가 주위 개발자분들에게 많이 받았던 질문이기도 해서이기 때문이다.
"검색창에 서비스 명을 검색하면 그냥 바로 나올 텐데, SEO 높아지는 게 무슨 효과가 있는 건가요?"
"SEO? 검색 결과에 조금 더 노출이 잘 되는게 그렇게 중요할까요?"

google 콴다 검색 결과 페이지
예를 들어, 검색창에 직접 '콴다'를 쳐서 검색 결과에 콴다가 나오는 것은, 검색 결과로 보여줄 Target이 확실하므로 SEO와는 연관이 적다...🙏 (아예 연관이 없다고는 하지 않겠다.)그러나 우리가 SEO에 신경 써야 할 요소는 'Target이 확실하지 않은 검색 결과'이다.
이해를 돕기 위해 아래에 예시를 하나 들어보자.우리는 맛집 정보를 제공하는 서비스를 운영 중이다.
유저들이 구글에 '강남역 맛집'이라고 쳤을 때 우리 사이트의 정보가 검색 결과 1페이지 상단에 있을 것이란 보장이 있는가? 만약 저 키워드로 우리 서비스가 검색 결과 최상단에 뜬다면 많은 유저들이 우리 서비스로 유입시키는 것이 가능할 것이다.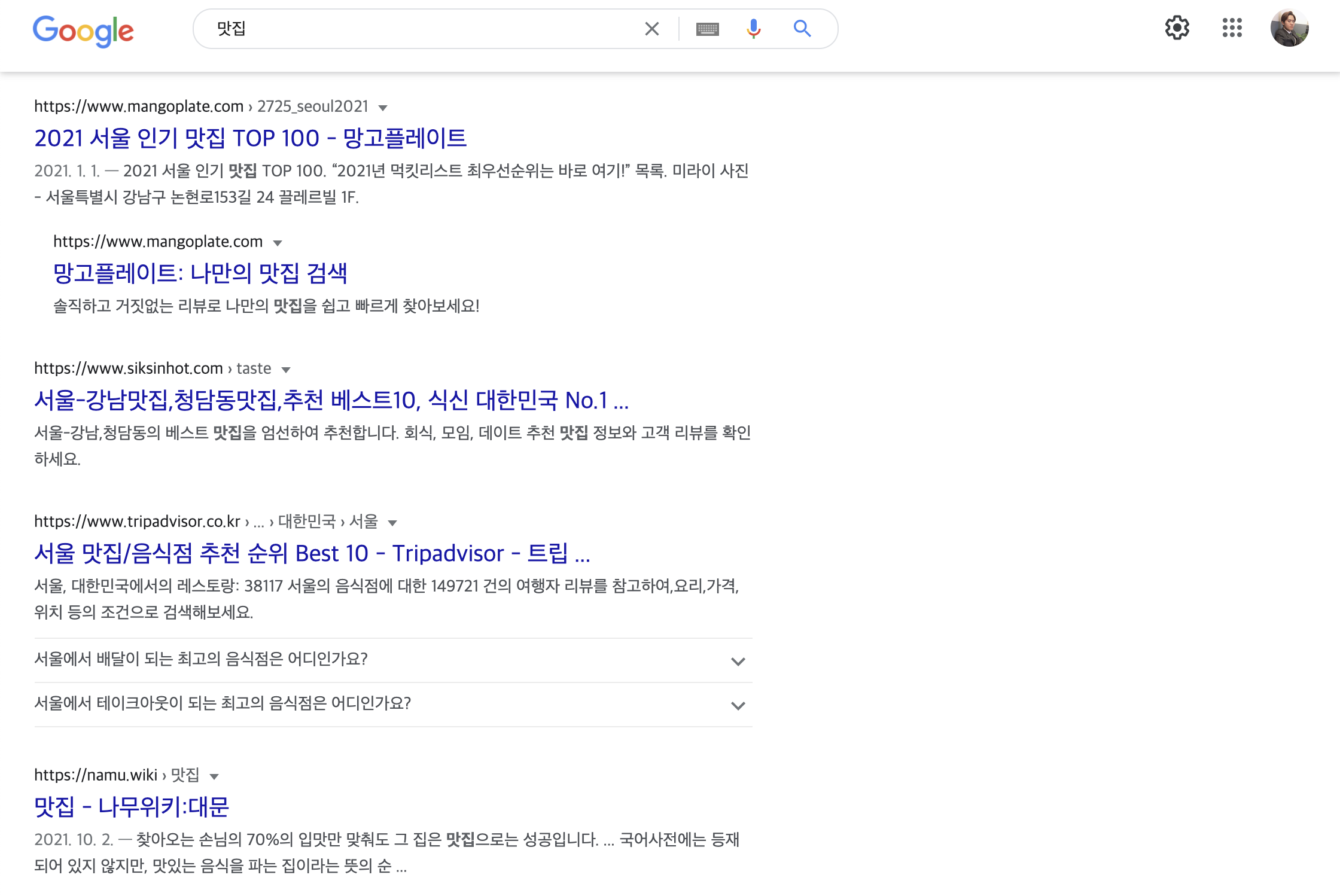
google 맛집 검색에 대한 결과 1페이지
검색 결과에 뜨기 쉬운 만큼 많은 유저들에게 우리 서비스가 많이 노출되며 인지도가 높아질 것이고, 우리 서비스를 많은 사람들에게 알리기 위해 사용될 광고 비용과 마케팅에 신경 써야 할 리소스를 줄일 수 있다.하지만 반대로 검색 결과 9페이지 정도에 머물러 있다 하면, 유저는 우리 사이트를 발견할 확률이 굉장히 낮을 것이고, 그만큼 우리 서비스를 알리기가 힘들게 된다.
SEO는 서비스 운영에 대한 큰 비용과 리소스를 절감시킬 수 있는 가장 중요한 수단이다. 그리고 SEO는 얼마나 검색 엔진(Search Engine)에 최적화되어 있는지에 대한 다른 경쟁 사이트와의 Score 싸움이다.
나는 이 SEO를 위해 프론트엔드 개발자로서 내가 해야만 했던 임무는, 가능한 모든 액션을 취해 웹 성능을 최대한 끌어올려 타 경쟁 사이트보다 조금이라도 더 빠르게 웹 페이지를 보여주도록 하는 작업인 것이다.
(웹 성능이 SEO Score의 전부가 아님을 오해하지 말기를 바란다. SEO Score에 미치는 요소는 다양하고 웹 성능은 그중 일부일 뿐이다.)
마치며
글을 쓰다 보니, 의도치 않게 SEO와 웹 성능을 여러 가지 최적화시킬 수 있는 방법을 소개하는 글이 되어버린 느낌이다. 그러나 내가 여기서 전달하고 싶은 메시지는 우리가 해결해야 하는 문제가 무엇이고, 그 문제를 어떻게 찾을 것이냐 이다.
위에 맨 처음에 상황을 가정했던 것처럼, 만약 팀 리더가 '최대한 할 수 있는 만큼 빠르게 페이지 화면이 띄어지도록 개선시켜 주세요'라고 미션을 준다면, 우리는 무엇을 해결해야 하는지 '문제 정의'부터 쉽지 않았을 것이다. 브라우저 동작원리를 모른다면 단순히 코드를 줄이고, 재활용성을 높이는 작업 외에 Low Level 단계의 개선점 찾아보려는 생각을 못했을 수도 있다.
이제 막 개발을 시작한 주니어 개발자들에겐 '개발을 잘하는 것' 이란, 코드를 예쁘게 짜고, 컴포넌트와 상태 설계를 잘하고, 요구하는 CSS 스타일을 이상 없이 잘 구현하는 것, 그리고 작업들을 정확하고 빠르게 하는 것이 전부라 생각했을 수도 있다.
하지만 우리가 앞으로 걸어야 되는 길은 '개발을 잘하는 것'이 아니라, '시니어 역량을 가지는 것'이다.
코드를 빠르고 정교하게 잘 구현하는 것은 물론, 우리가 해결해야 하는 문제가 무엇인지, 이 문제를 해결하기 위해 할 수 있는 액션이 무엇인지를 정의할 수 있는 것, 그리고 예상치 못한 문제가 닥쳤을 때 그 원인을 파악하는 것.
이러한 역량들이 브라우저 동작원리뿐 아니라 HTTP, Javascript 엔진, Event Loop 등 프론트엔드 개발자들에게 필요한 기본 개념을 기반으로 나타나는 것이다. 그러니 우리는 꾸준히 기본 지식을 탄탄히 익혀 나가야만 한다.이 글이 많은 주니어 개발자들에게 도움이 되었으면 좋겠다.
반응형'개발 블로깅 > Improving Performance' 카테고리의 다른 글
Brotli 압축방식(Compression)을 통한 웹 성능 최적화 (0) 2022.06.30 Next.js Lazy Hydration으로 웹 성능 향상시키기(HTML은 유지하고 Script는 걸러내자) (2) 2021.12.02 [2021.05.02] 웹 성능 최적화를 위한 Webpack Bundle Size 줄이기 (0) 2021.05.02 웹 성능 최적화를 위한 Tree Shaking 소개 (2) 2021.03.27 웹 성능 최적화를 위한 Image Lazy Loading 기법 (18) 2020.11.29